我之前手里有 3 小时自己的中文普通话读稿录音。
当时冒出来一个念头:能不能在本地克隆一个自己的声音?
不是为了炫技。
而是做内容的人都懂,录音很烦。
一段文案要重录好几遍,嘴瓢、忘词、情绪不对,都得重来。
如果以后我输入一段文字,Mac mini 能用我的声音先生成一版音频,那很多内容就能先跑起来。
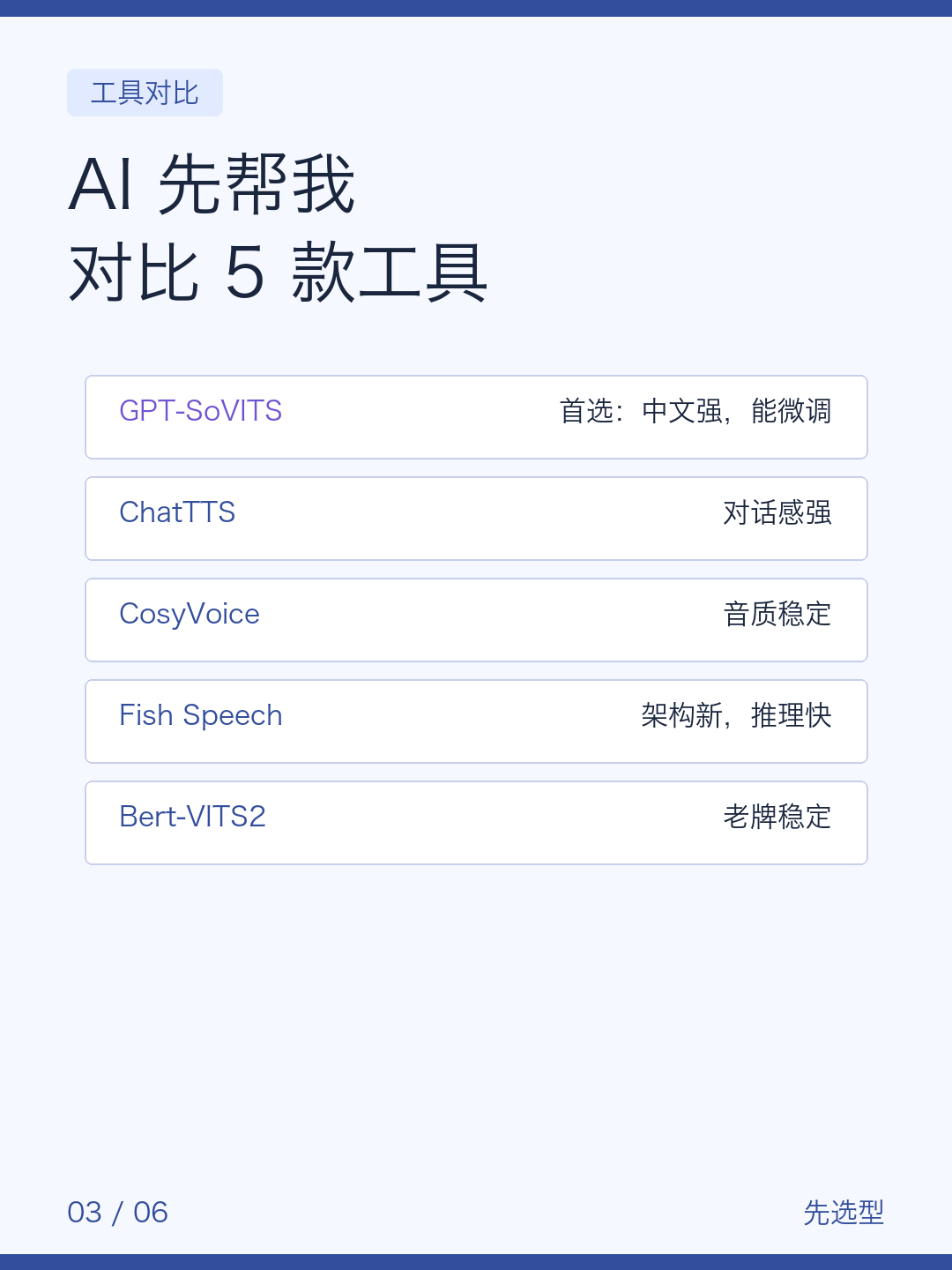
我让 AI 先帮我选工具。
它对比了 5 个方向:GPT-SoVITS、ChatTTS、CosyVoice、Fish Speech、Bert-VITS2。
最后建议我先用 GPT-SoVITS。
原因很简单:中文支持强,能用短音频做零样本,也能用我这 3 小时素材继续微调。
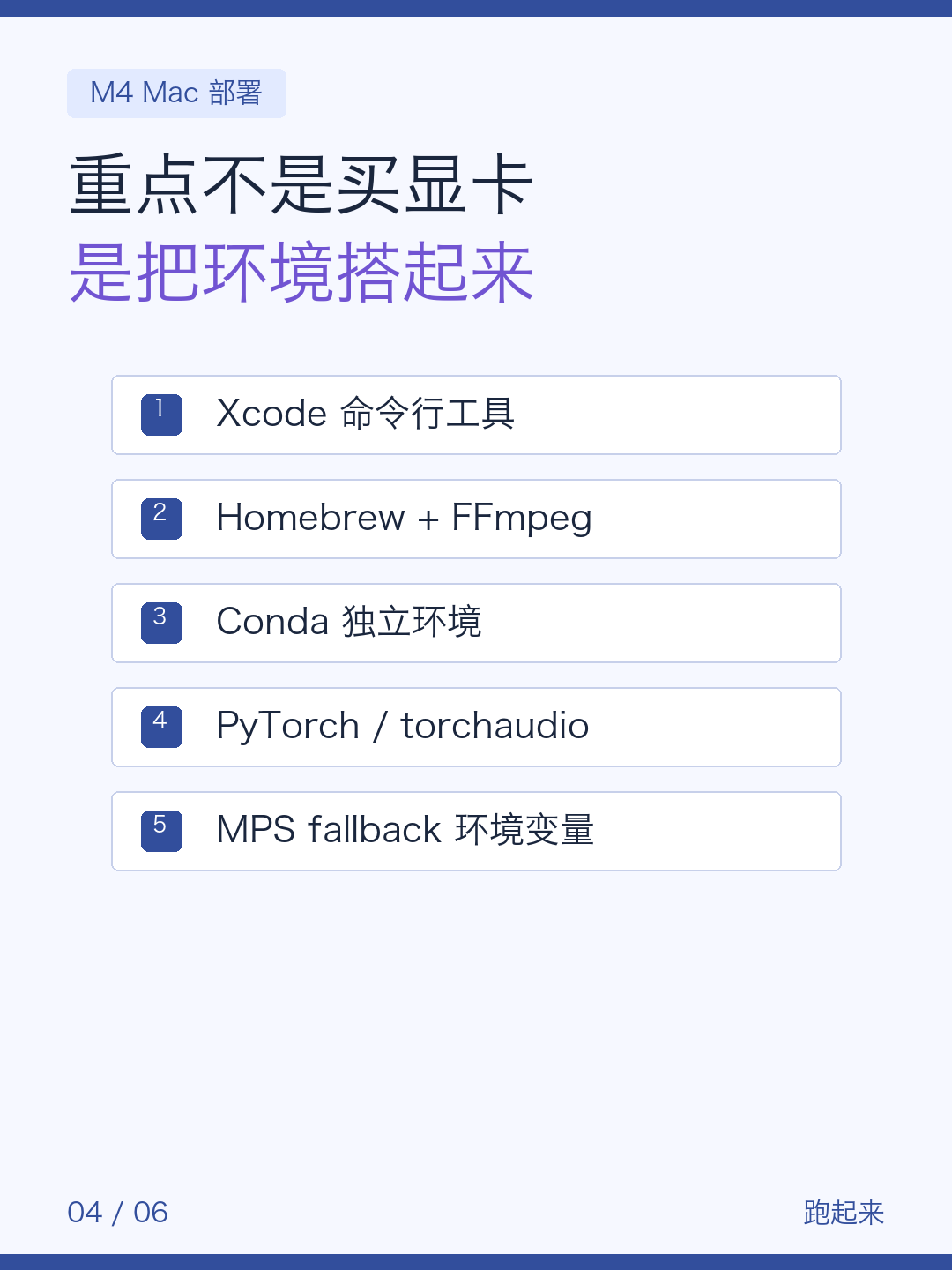
我的设备是 M4 Mac mini,所以重点不是买显卡,而是把本地环境搭起来。
第一步装基础工具:Xcode 命令行工具、Homebrew、FFmpeg。
FFmpeg 是处理音频必备的,后面切分、转格式都绕不开。
第二步装 Conda,单独建 Python 环境,避免把系统环境弄乱。
第三步拉 GPT-SoVITS 代码,装 PyTorch、torchaudio 这些依赖。
Mac 上还要注意 MPS 加速,所以运行前加了:
PYTORCH_ENABLE_MPS_FALLBACK=1
真正麻烦的是后面。
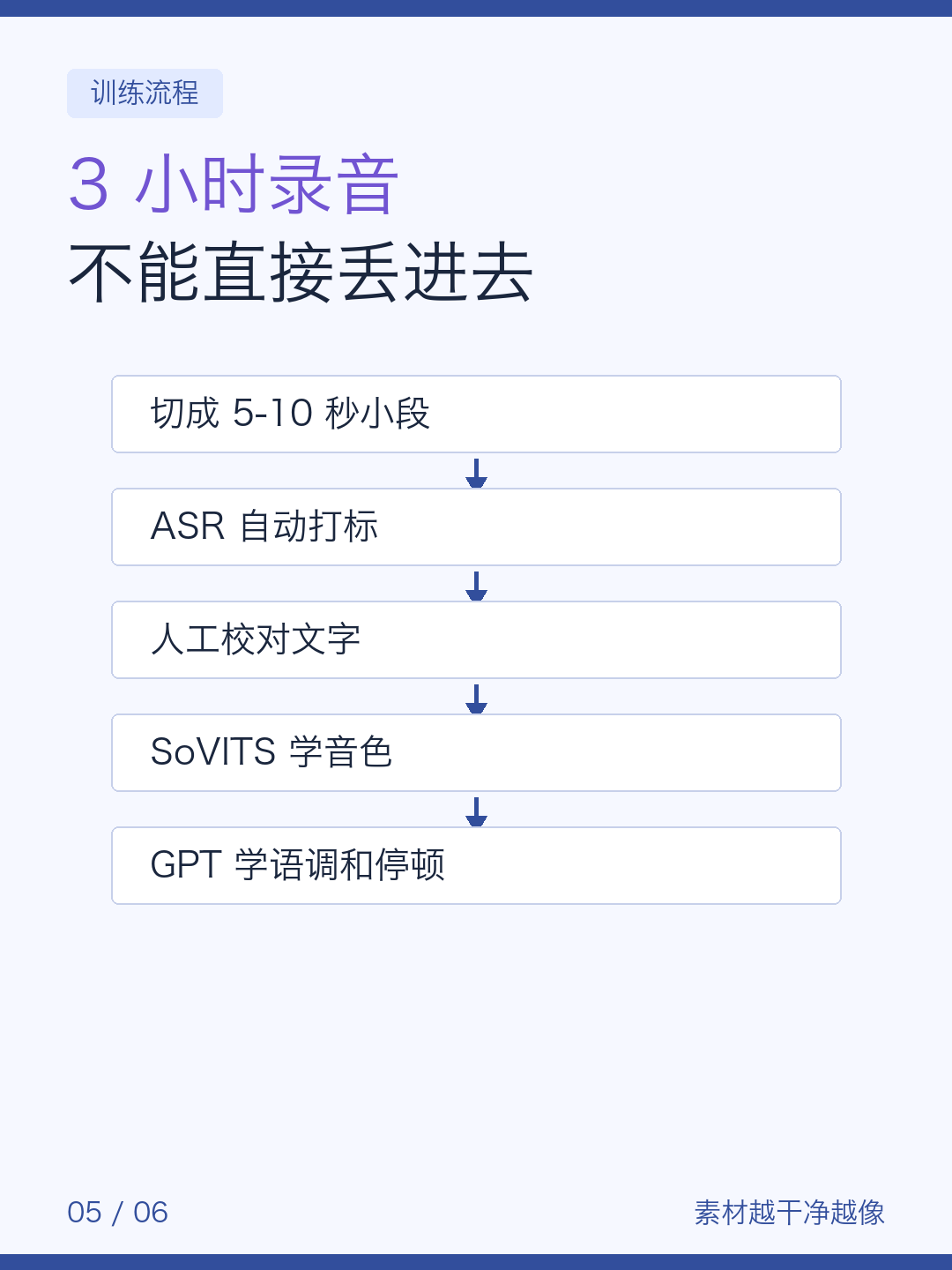
3 小时录音不是直接丢进去就万事大吉。
要先切成 5-10 秒的小段,再做 ASR 打标,识别文字还要人工校对。
声音像不像,很大程度取决于这些素材干不干净、文字准不准。
训练也分两层:SoVITS 学音色,GPT 学语调、停顿和口吻。
这里我不会说它已经稳定商用了。
现在更准确的说法是:已经能部署、能跑,后面还要继续调参和验证自然度。
但这件事让我很确定一点:
AI 对内容创业者的价值,不只是帮你写稿。
它还能把你的声音、文档、录音、流程,慢慢变成可复用资产。
这个岗位,我会叫它:AI 声音助理。